OneSpan Sign Developer: Document Extraction and Customized Field Validator

When creating an e-transaction, creating individual fields and signatures can be a tedious, time-consuming activity. Luckily, OneSpan Sign has a feature that can streamline this task: Document Extraction.
Document Extraction enables you to automatically create all signatures and fields with less code. Rather than building your form manually, you can upload a PDF form and tell OneSpan Sign where you want your fields (signature /date /text field, etc.) to be on the document. So long as the property name of the PDF form follows specific OSS grammar, OneSpan Sign can determine which type of fields you want and which signer and approval you want this field to be bound to.
Document Extraction in OneSpan Sign
In this blog, we will use the same example that appears in our official guidance, where you can find the PDF file and code snippets to create the same transaction. Below is a screenshot of the PDF forms we used in this scenario.
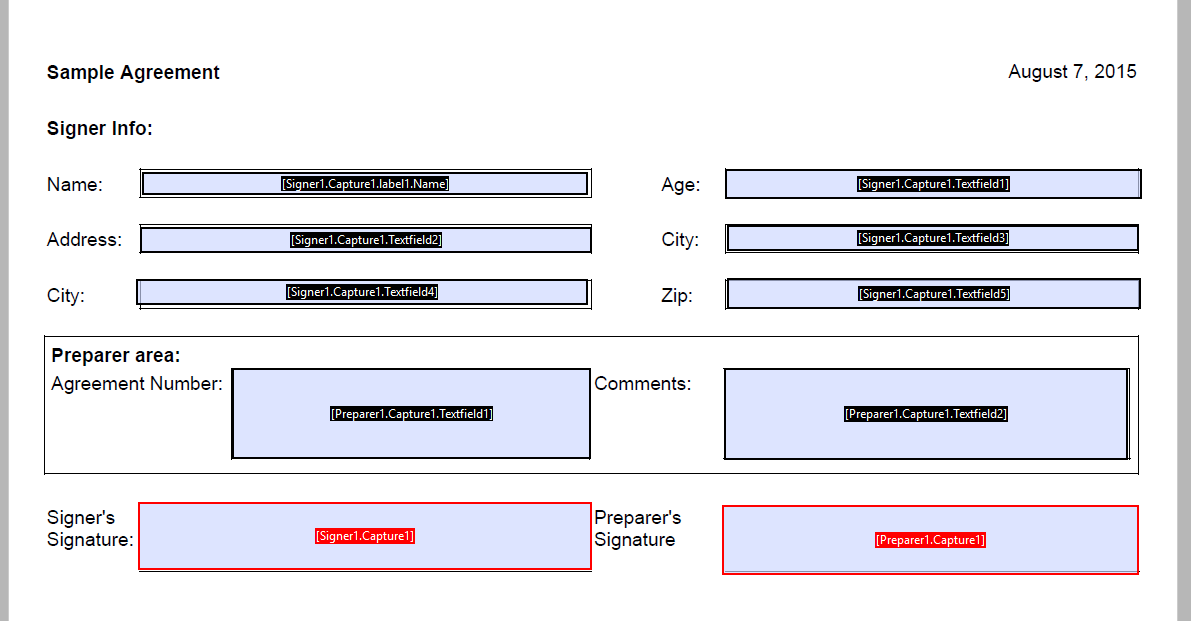
So, our example is as simple as this: 2 signers, 1 document and 1 signature per signer. Role1 with id of “Signer1” has 5 fields bound to the signature while Role2 with id of “Preparer1” has 2 fields bound to the signature.
Learn more about Document Extraction here .
Customized Field Validator
Field validators enable you to restrict the range of acceptable values for an unbounded field. While if you are using the Document Extraction Feature, it’s not possible to assign or retrieve document/approval/fields IDs in the call when creating the transaction. Which means, in order to add field validator, you must make extra API/SDK calls.
In this section, we will dive into how to add a validator for the field “ZIP” to validate whether the signer’s input obeys the format of Canadian Postal ZIP codes. Here are two steps you must follow:
(1) Create the package and leave it in "DRAFT" status.
(2) Add a validation for the specific field. Because, OneSpan Sign will provide field names as per your PDF form property name, you do not need to assign individual IDs.
Locate Your Signature Approval
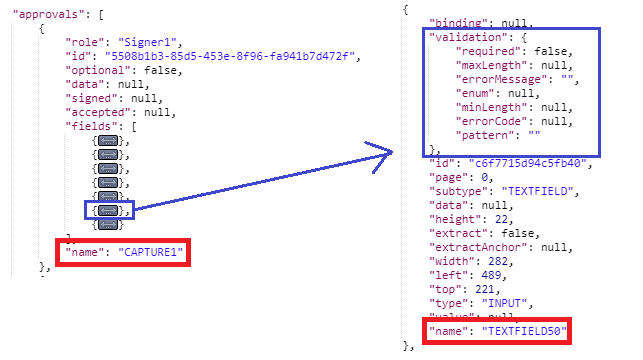
To locate your signature approval, the approval name will follow a simple structure: “{SUBTYPE}{N}”. It is constructed by combining the upper case of your subtype (capture/fullname/initial) plus the ending number in your PDF form.
For example, if your signature field is named [Signer1.Capture1], your approval’s name will be “CAPTURE1”. If your signature field is [Signer1.Fullname2], your approval’s name will be “FULLNAME2”, and so forth.
Locate your TextField
A field with type of “TEXTFIELD”, however, follows a different naming structure: “TEXTFIELD{10*N}”. This structure is all upper case plus 10 multiplied by the ending number in your PDF form.
For example, if your “ZIP” field is named by [Signer1.Capture1.Textfield5], your textfield’s name will be “TEXTFIELD50”.
From here, the rest of the work is easy, we just need to add the Regex for Canadian Postal ZIP codes:
Regex : ^(?!.*[DFIOQU])[A-VXY][0-9][A-Z] ?[0-9][A-Z][0-9]$
Here’s the code snippet in Java SDK:

Note:
- Remember to add setMinLength() function, because the default minLength value is 0, in which case the validator won’t work.
And the result of the code:
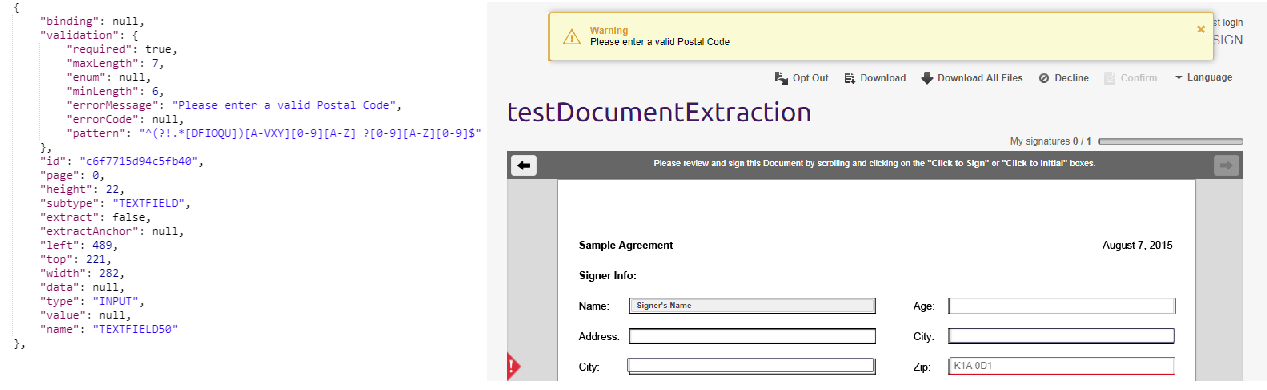
So, by following these few steps, we successfully add field validators to fields in the condition of using Document Extraction. And the way we locate approval and textfields also works in other situations when you want to further customize settings on top of Document Extraction.
To download the code, you can find it at our Code Share.
If you have any questions regarding this blog or anything else concerning integrating OneSpan Sign into your application, visit the Developer Community Forums. Your feedback matters to us!


